









File Commands
List files in the directory
ls
Note : In Linux directory is like a folder in Windows OSList all files:
ls -aShow the directory in which you are currently working in
pwdCreate a new directory
mkdir directoryname
Remove/delete a file
rm filename
Remove/delete a directory recursively
rm -r directorynameRecursively remove/delete a directory without requiring confirmation
rm -rf directorynameCopy the contents of one file to another file
cp filename1 filename2
Recursively copy the contents of one file to a second file
cp -r directoryname1 directoryname2Rename [file_name1] to [file_name2]
mv filename1 filename2
What is a symlink in Linux?
A symbolic link (also known as a symlink or soft link) is a special type of file in a Linux operating system that contains a reference to another file or directory. The reference can be either an absolute path or a relative path, and it specifies the location of the file or directory that the symbolic link is pointing to.
Symbolic links are similar to shortcuts in Windows, but they work differently. Unlike shortcuts, which are essentially pointers to files or directories that are stored within the shortcut file, symbolic links are actual files that contain a reference to another file or directory. This means that if you delete the original file or directory that the symbolic link is pointing to, the symbolic link will still exist, but it will be broken and will not be able to access the original file or directory.
Symbolic links can be useful in a variety of situations. For example, you can use them to create aliases for frequently used files or directories, or to make it easier to access files or directories that are located in different parts of the file system. You can also use symbolic links to create multiple copies of a file or directory without actually duplicating the data, which can save space on your hard drive.
To create a symbolic link in Linux, you can use the ln command with the -s option. For example, to create a symbolic link to a file called file.txt in the current directory, you would enter the following command:
ln -s file.txt link_to_file
This would create a symbolic link called link_to_file that points to file.txt. When you access link_to_file, it will behave as if you are accessing file.txt.
Create a symbolic link to a file
ln -s /path/to/filename linkname
Create a new file using touch
touch filename
Show the contents of a file
more filename
or
cat filename
Append file contents to another file
cat filename1 >> filename2Display the first 10 lines of a file
head filename
Display the last 10 lines of a file
tail filenameEncrypt a file
gpg -c filename
Decrypt a file
gpg filename.gpgShow the number of words, lines, and bytes in a file
wc filenameWhat is xargs command ?
xargs is a command that allows you to build and execute commands from standard input. It reads input from stdin, or from a file if the -a option is used, and then executes the command one or more times with any arguments specified.
Here’s a simple example of using xargs to delete all of the .txt files in the current directory:
$ ls *.txt | xargs rm
This command lists all of the .txt files in the current directory, and then passes the list to xargs, which executes the rm command (to delete a file) for each file in the list.
You can also use xargs to execute a command with a fixed set of arguments, followed by the input from stdin. For example, to copy all of the .txt files in the current directory to a backup directory, you could use the following command:
$ ls *.txt | xargs -I{} cp {} backup/
This command uses the -I option to specify a placeholder ({}) for the input from stdin. The cp command is executed once for each .txt file in the current directory, with the filename being passed as an argument to the cp command (replacing the {} placeholder).
There are many other options and usage scenarios for xargs, but these are some of the most common and simple examples.
List number of lines/words/characters in each file in a directory
ls | xargs wc directorynameWhat is cut command ?
cut is a command-line utility that is used to extract specific fields or columns of text from a file or input. It reads input from a file or stdin and prints selected fields to stdout.
The -d option specifies the delimiter character that is used to split the input into fields.
Cut a section of a file and print the result to standard output
cut -d[delimiter] [filename]Cut a section of piped data and print the result to standard output
[data] | cut -d[delimiter]Print all lines matching a pattern in a file
awk '[pattern] {print $0}' [filename]
awk is a utility that searches for patterns in text files and performs actions on the lines that match the pattern. In this specific command, awk is searching for a pattern specified within the square brackets ([pattern]) in the specified file ([filename]). If a line in the file matches the pattern, the action specified within the curly braces ({print $0}) is performed.
In this case, the action is to print the entire line ($0 is a special variable in awk that refers to the entire line). So, this command will search the specified file for lines that match the pattern and print those lines to the terminal.
For example, if the file example.txt contained the following lines:
apple orange
banana cherry
grapefruit mango
pear raspberry
And the command awk '/grapefruit/ {print $0}' example.txt was run, the output would be:
grapefruit mango
This is because the pattern /grapefruit/ matches the line containing “grapefruit” and the action specified in the curly braces is to print that line.
Overwrite a file to prevent its recovery, then delete it
shred -u [filename]shred is a utility that can be used to securely delete files by overwriting the data in the file multiple times, making it difficult or impossible to recover the original data.
The -u option is used to delete a file by overwriting its data and then removing the file. This option can be used to delete a single file or multiple files.
For example, the command shred -u file1 file2 file3 would delete the files file1, file2, and file3 by overwriting their data and then removing the files.
It’s important to note that shred can only be used to delete regular files and cannot be used to delete directories. To delete a directory, you can use the rm command with the -r option to recursively delete the directory and its contents.
It’s also worth noting that shred is not foolproof and it is possible for data to be recovered from a file that has been shredded, depending on the level of scrutiny and the tools being used. However, shred can be a useful tool for securely deleting sensitive data that you no longer need.
Compare two files and display differences
diff [file1] [file2]Read and execute the file content in the current shell
source [filename]Sort file contents and print the result in standard output
sort [options] filenamesort is a command-line utility that can be used to sort lines of text alphabetically or numerically. It is commonly used to sort the output of other commands or to sort the contents of a file.
Here is an example of how sort can be used:
sort [options] [file][file] is the name of the file that you want to sort. If no file is specified, sort will read from standard input.
[options] is an optional list of flags that can be used to modify the behavior of sort. Some common options include:
-n: Sort numerically instead of alphabetically-r: Reverse the sort order-k: Sort based on a specific field or range of fields-t: Specify the field delimiter (default is tab)-o: Write the sorted output to a file instead of standard output
Here are some examples of how sort can be used:
- To sort the contents of a file alphabetically:
sort file.txt - To sort the contents of a file numerically:
sort -n file.txt - To sort the contents of a file in reverse order:
sort -r file.txt - To sort the output of the
lscommand alphabetically:ls | sort
sort is a useful tool for organizing and analyzing data, and it can be used in a variety of contexts.
-k and -t are options that can be used with the sort command to specify the field or fields on which to sort and the field delimiter, respectively.
-k is used to specify a field or range of fields on which to sort. The syntax for -k is -k[start],[end]. start and end are the starting and ending field numbers, respectively, and both are optional. If start is not specified, sort will use the first field as the starting point. If end is not specified, sort will use the last field as the ending point.
Here are some examples of how -k can be used:
- To sort a file based on the second field:
sort -k2 file.txt - To sort a file based on the second and third fields:
sort -k2,3 file.txt - To sort a file based on the second field, with the third field as a tiebreaker:
sort -k2,2 -k3,3 file.txt
-t is used to specify the field delimiter, which is the character that separates the fields in the input data. By default, the field delimiter is a tab character. However, if the input data uses a different character as the field delimiter, you can use -t to specify that character.
For example, to sort a file with the field delimiter set to a comma (,), you can use the following command: sort -t, file.txt
-k and -t can be used together to sort a file based on specific fields and with a specific field delimiter. For example: sort -t, -k2,3 file.txt
Directory Navigation
Move up one level in the directory tree structure
cd..Change directory to $HOME
cdChange location to a specified directory
cd /directorynameFile Compression
Difference between archive and compress file
An archive is a file that contains one or more other files, often in compressed form, along with metadata about the archived files. The purpose of an archive is to package multiple files together into a single file for easier distribution or backup. Examples of archive formats include tar, zip, and rar.
Compression is the process of reducing the size of a file by removing redundancy or irrelevance in the data it contains. Compressing a file can make it easier to store or transmit, as it takes up less space on a hard drive or takes less time to transmit over a network. There are various algorithms for compressing files, and different types of files may be more or less amenable to compression.
An archive file can contain compressed files, but not all archive files are compressed. For example, a tar archive file can contain compressed files, but the tar file itself is not compressed. On the other hand, a gzip-compressed tar file is both an archive and a compressed file, as the tar file contains other files and the gzip compression reduces the size of the overall file.
tar command
The tar command stands for Tape ARchive. It is a utility for bundling a set of files and directories into a single file for easier distribution or backup.
The tar command has many options, but the cf options are commonly used to create a new tar archive file. The c option tells tar to create a new archive, and the f option specifies the name of the archive file.
For example, the command tar cf compressed_file.tar file_name would create a new tar archive file called compressed_file.tar and add the file file_name to the archive. This command would create a tar archive of the file file_name, but it would not compress the file.
If you want to compress the tar archive, you can use the z option to compress the file using gzip. For example, the command tar czf compressed_file.tar.gz file_name would create a gzip-compressed tar archive file called compressed_file.tar.gz and add the file file_name to the archive.
You can also specify multiple files or directories to add to the tar archive by listing them after the name of the tar archive file. For example, the command tar cf compressed_file.tar file1 file2 directory1 would create a tar archive file called compressed_file.tar and add the files file1 and file2 and the directory directory1 to the archive.
Archive an existing file
tar cf compressed_file.tar file_nameCreate a gzip compressed tar file
tar czf compressed_file.tar.gz file_nameExtract an archived file
tar xf [compressed_file.tar]File Transfer
Copy a file to a server directory securely
scp [file_name.txt] [server/tmp]Synchronize the contents of a directory with a backup directory
rsync -a [/your/directory] [/backup/]
Users and Groups
See details about the active users
idShow last system logins
lastDisplay who is currently logged into the system with the who command
whoShow which users are logged in and their activity
wAdd a new group
groupadd [group_name]Add a new user
adduser [user_name]Add a user to a group
usermod -aG [group_name] [user_name]Temporarily elevate user privileges to superuser or root
sudo [command_to_be_executed_as_superuser]Delete a user
userdel [user_name] Modify user information
usermodChange directory group
chgrp [group-name] [directory-name]
Package Installation
List all installed packages with yum
yum list installedFind a package by a related keyword
yum search [keyword]Show package information and summary
yum info [package_name]Install a package using the YUM package manager
yum install [package_name.rpm]Install a package using the DNF package manager
dnf install [package_name.rpm]Install a package using the APT package manager
apt install [package_name]Install an .rpm package from a local file
rpm -i [package_name.rpm]Remove an .rpm package
rpm -e [package_name.rpm]Install software from source code
tar zxvf [source_code.tar.gz]
cd [source_code]
./configure
make
make installProcess Related
See a snapshot of active processes
psShow processes in a tree-like diagram
pstreeDisplay a memory usage map of processes
pmapSee all running processes
topTerminate a Linux process under a given ID
kill [process_id]Terminate a process under a specific name
pkill [proc_name]Terminate all processes labelled “proc”
killall [proc_name]List and resume stopped jobs in the background
bgBring the most recently suspended job to the foreground
fgBring a particular job to the foreground
fg [job]List files opened by running processes
lsofCatch a system error signal in a shell script
trap "[commands-to-execute-on-trapping]" [signal]Pause terminal or a Bash script until a running process is completed
waitRun a Linux process in the background
nohup [command] &
System Management and Information
Show system information
uname -r See kernel release information
uname -a Display how long the system has been running, including load average
uptime See system hostname
hostnameShow the IP address of the system
hostname -i List system reboot history
last reboot See current time and date
dateQuery and change the system clock with
timedatectl Show current calendar (month and day)
calList logged in users
wSee which user you are using
whoamiShow information about a particular user
finger [username]View or limit system resource amounts
ulimit [flags] [limit]Schedule a system shutdown
shutdown [hh:mm]Shut Down the system immediately
shutdown nowAdd a new kernel module
modprobe [module-name]Disk Usage
You can use the df and du commands to check disk space in Linux.
See free and used space on mounted systems
df -hShow free inodes on mounted filesystems
df -iDisplay disk partitions, sizes, and types with the command
fdisk -lSee disk usage for all files and directory
du -ahShow disk usage of the directory you are currently in
du -shDisplay target mount point for all filesystem
findmntMount a device
mount [device_path] [mount_point]SSH Login
Connect to host as user
ssh user@hostSecurely connect to host via SSH default port 22
ssh hostConnect to host using a particular port
ssh -p [port] user@hostConnect to host via telnet default port 23
telnet hostFile Permission
Check files and its permission in current directory
ls -lrt
or
ls -lNote :
The ls command is used to list the files and directories in a directory. The -l flag tells ls to display the files in a long format, which includes additional information about the files such as their permissions, owner, size, and modification date. The -r flag reverses the order in which the files are listed, so that the files are listed in descending rather than ascending order. The -t flag sorts the files by modification time, so that the files that have been most recently modified are listed first.
So, the ls -lrt command will list the files in a directory in long format, with the most recently modified files listed first.
Lets checkout one example with ls -l command
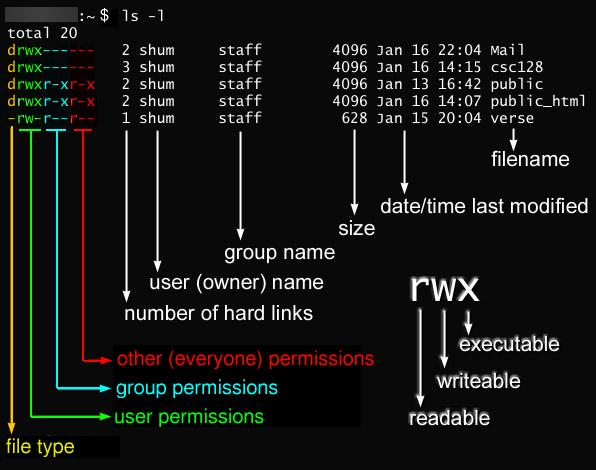
chmod is a command used to change the permissions of a file or directory in a Unix-like operating system. The permissions determine which users or groups are able to read, write, or execute a file.
The basic syntax for using chmod is as follows:
chmod [permissions] [file or directory]
There are two ways to specify the permissions: using symbolic notation or using octal notation.
In symbolic notation, the permissions are specified using letters to represent the three types of permissions: r for read, w for write, and x for execute. These letters are placed after a + or - symbol to indicate whether the permissions are being added or removed. For example, to add read and write permissions for the owner of a file, you could use the following command:
chmod u+rw file.txtIn octal notation, the permissions are specified using a three-digit number. Each digit represents the permissions for a different class of users: the owner of the file, the group to which the file belongs, and all other users. The digits are calculated by adding together the values 4 (read), 2 (write), and 1 (execute) as needed. For example, the octal value 644 represents read and write permissions for the owner and read-only permissions for the group and other users. To set the permissions of a file to 644, you could use the following command:
chmod 644 file.txt
Chown command in Linux changes file and directory ownership.
Assign read, write, and execute permission to everyone
chmod 777 [file_name]Give read, write, and execute permission to owner, and read and execute permission to group and others
chmod 755 [file_name]Assign full permission to owner, and read and write permission to group and others
chmod 766 [file_name]Change the ownership of a file
chown [user] [file_name]Change the owner and group ownership of a file
chown [user]:[group] [file_name]
Network
List IP addresses and network interfaces
ip addr showAssign an IP address to interface eth0
ip address add [IP_address]Display IP addresses of all network interfaces with
ifconfigSee active (listening) ports with the netstat command
netstat -pnltuShow tcp and udp ports and their programs
netstat -nutlpDisplay more information about a domain
whois [domain]Show DNS information about a domain using the dig command
dig [domain] Do a reverse lookup on domain
dig -x hostDo reverse lookup of an IP address
dig -x [ip_address]Perform an IP lookup for a domain
host [domain]Show the local IP address
hostname -IDownload a file from a domain using the wget command
wget [file_name]Receive information about an internet domain
nslookup [domain-name]Save a remote file to your system using the filename that corresponds to the filename on the server
curl -O [file-url]Variables
Assign an integer value to a variable
let "[variable]=[value]"Export a Bash variable
export [variable-name]Declare a Bash variable
declare [variable-name]= "[value]"List the names of all the shell variables and functions:
setDisplay the value of a variable
echo $[variable-name]Shell Command Management
Create an alias for a command
alias [alias-name]='[command]'Set a custom interval to run a user-defined command
watch -n [interval-in-seconds] [command]Postpone the execution of a command
sleep [time-interval] && [command]Create a job to be executed at a certain time (Ctrl+D to exit prompt after you type in the command)
at [hh:mm]Display a built-in manual for a command
man [command]Print the history of the commands you used in the terminal
historyLinux Keyboard Shortcuts
Kill process running in the terminal
Ctrl + CStop current process
Ctrl + ZThe process can be resumed in the foreground with fg or in the background with bg.
Cut one word before the cursor and add it to clipboard
Ctrl + WCut part of the line before the cursor and add it to clipboard
Ctrl + UCut part of the line after the cursor and add it to clipboard
Ctrl + KPaste from clipboard
Ctrl + YRecall last command that matches the provided characters
Ctrl + RRun the previously recalled command
Ctrl + OExit command history without running a command
Ctrl + GRun the last command again
!!Log out of the current session
exitfile
The file command in Linux is used to determine the type of a file. It reads the contents of a file and attempts to identify the file type based on certain characteristics of the content. The file type is then printed to the standard output.
Here is an example of using the file command:
$ file test.txt
test.txt: ASCII text
In this example, the file command determined that the file test.txt is an ASCII text file.
‘cmp’ command
The cmp command in Linux is a utility for comparing the contents of two files. It reads the two files specified as arguments and compares them byte by byte. If the files are different, cmp will output the byte number and the differing bytes. If the files are the same, cmp will not output anything.
Here is an example of using cmp to compare two files:
cmp file1 file2If the files are different, cmp will output something like this:
file1 file2 differ: byte 12, line 2This indicates that the two files differ at byte 12 in the second line of the file.
You can also use the -l option to display a list of the differing bytes and their locations:
cmp -l file1 file2
This will output a list of the form:
12 34
13 35
14 36
...Each line in the output represents a pair of bytes, with the first byte coming from file1 and the second byte coming from file2. The numbers on the left represent the byte offset from the start of the file.
You can also use the -s option to suppress output and just exit with a status code indicating whether the files are the same (exit code 0) or different (exit code 1). This can be useful if you want to use cmp in a script and just check the exit code.
cmp -s file1 file2‘comm’ command
The comm command is a Unix utility used to compare two sorted files line by line. It takes two input files and produces three output columns, with lines unique to the first file, lines unique to the second file, and lines common to both files.
Here is the basic syntax of the comm command:
comm [OPTION]... FILE1 FILE2The comm command reads the two input files and compares them line by line. If a line is present in both files, it is considered a common line. If a line is present only in the first file, it is considered unique to the first file. If a line is present only in the second file, it is considered unique to the second file.
By default, comm produces three output columns, separated by tabs. The first column contains the lines unique to the first file, the second column contains the lines unique to the second file, and the third column contains the lines common to both files.
Here is an example of how to use comm to compare two files:
$ cat file1.txt
apple
banana
cherry
$ cat file2.txt
apple
banana
date
fig
To compare the two files, you can use the comm command as follows:
$ comm file1.txt file2.txt
apple
banana
cherry
date
fig
In this example, the output shows that apple and banana are common to both files, while cherry is unique to the first file and date and fig are unique to the second file.
You can use various options with the comm command to customize its output. For example, the -1 option suppresses the output of the first column, the -2 option suppresses the output of the second column, and the -3 option suppresses the output of the third column.
‘diff’ command
The diff command is a utility in Linux that is used to compare the differences between two files or directories. It compares the contents of two files line by line and prints out the lines that are different.
Here are some examples of how to use the diff command:
- To compare the contents of two files:
diff file1.txt file2.txt
The diff file1.txt file2.txt command compares the contents of two files, file1.txt and file2.txt, line by line and prints out the lines that are different. The output of the diff command will show you which lines are different and how they differ.
For example, if file1.txt contains the following text:
Line 1
Line 2
Line 3
Line 4
And file2.txt contains the following text:
Line 1
Line 3
Line 4
Line 5
Then the diff command would output something like this:
2d1
< Line 2
4a4
> Line 5








